научный
журнал
Срочная публикация научной статьи
+7 995 770 98 40
+7 995 202 54 42
info@journalpro.ru

Методы машинного обучения для прогнозирования позиций сайтов в поисковой выдаче

Рубрика: Технические науки
Журнал: «Евразийский Научный Журнал №2 2026» (февраль, 2026)
Количество просмотров статьи: 186
Показать PDF версию Методы машинного обучения для прогнозирования позиций сайтов в поисковой выдаче
Чурилов Александр Александрович
Генеральный директор ООО "Айсео", Москва
E-mail: a.churilov@iseo.ru
Аннотация. Данная статья представляет комплексный анализ методов машинного обучения для прогнозирования позиций веб-сайтов в результатах поисковых систем. Исследование рассматривает различные алгоритмы машинного обучения, включая методы ансамблирования на основе деревьев решений (Random Forest, XGBoost, LightGBM), нейронные сети и глубокое обучение. Особое внимание уделяется проблеме дисбаланса классов, характерной для датасетов в области поисковой оптимизации, где сайты с высокими позициями составляют малую долю от общего числа наблюдений. Представлены методы решения данной проблемы, включая техники ресемплирования (SMOTE, ADASYN) и алгоритмические подходы (cost-sensitive learning). Экспериментальные результаты на датасете из 3500 страниц электронной коммерции демонстрируют, что XGBoost и LightGBM с применением весов классов достигают наилучшей производительности с F1-мерой
Ключевые слова: машинное обучение, поисковая оптимизация, прогнозирование ранжирования, дисбаланс классов, XGBoost, SMOTE, SHAP-анализ, градиентный бустинг.
MACHINE LEARNING METHODS FOR SEARCH ENGINE RANKINGS PREDICTION: A COMPREHENSIVE ANALYSIS
Churilov Alexander Alexandrovich
CEO of ISEO LLC, Moscow
E-mail: a.churilov@iseo.ru
Abstract. This article presents a comprehensive analysis of machine learning methods for predicting website positions in search engine results. The study examines various machine learning algorithms, including tree-based ensemble methods (Random Forest, XGBoost, LightGBM), neural networks, and deep learning approaches. Special attention is paid to the class imbalance problem inherent in SEO datasets, where high-ranking websites constitute a small fraction of total observations. Methods for addressing this problem are presented, including resampling techniques (SMOTE, ADASYN) and algorithmic approaches (cost-sensitive learning). Experimental results on a dataset of 3,500 e-commerce pages demonstrate that XGBoost and LightGBM with class weights achieve the best performance with F1-scores of
Keywords: machine learning, search engine optimization, ranking prediction, class imbalance, XGBoost, SMOTE, SHAP analysis, gradient boosting.
Введение
Поисковая оптимизация (SEO) превратилась в критически важный компонент стратегий цифрового маркетинга, поскольку компании конкурируют за видимость на страницах результатов поисковых систем (SERP). При том, что Google обрабатывает более 8,5 миллиардов поисковых запросов ежедневно (Internet Live Stats, 2023), достижение и поддержание высоких позиций в выдаче становится всё более сложной и конкурентной задачей. Алгоритмы, определяющие эти позиции, отличаются сложностью, постоянно эволюционируют и в значительной степени не раскрываются компаниями-поисковиками, что создаёт серьёзные проблемы для владельцев веб-сайтов и SEO-специалистов.
В последние годы машинное обучение (МО) зарекомендовало себя как перспективный подход к пониманию, прогнозированию и оптимизации позиций в поисковых системах. В отличие от традиционных статистических методов, алгоритмы машинного обучения способны выявлять сложные закономерности в больших массивах данных и адаптироваться к изменяющимся условиям — характеристики, хорошо согласующиеся с динамичной природой алгоритмов поисковых систем. Настоящее исследование рассматривает различные методы машинного обучения для прогнозирования позиций в поисковой выдаче, оценивая их эффективность, ограничения и практические применения.
Исследование отвечает на несколько ключевых вопросов: какие алгоритмы машинного обучения наиболее эффективны для прогнозирования позиций в поисковых системах? Какие признаки вносят наиболее значительный вклад в предсказания ранжирования? Как эти методы могут быть эффективно реализованы SEO-практиками? И каковы уникальные проблемы применения машинного обучения к прогнозированию поисковых позиций, в частности, проблема дисбаланса классов, которая часто встречается в SEO-датасетах?
Синтезируя результаты множественных исследований и рассматривая практические применения, данная работа предоставляет комплексный анализ подходов машинного обучения к прогнозированию поисковых позиций, предлагая ценные инсайты как для исследователей, так и для практиков в области поисковой оптимизации.
Теоретические основы ранжирования в поисковых системах
Эволюция алгоритмов поисковых систем. Поисковые системы претерпели значительную эволюцию с момента своего появления. Ранние поисковые системы, такие как AltaVista и Yahoo, опирались преимущественно на простое сопоставление ключевых слов и мета-теги. Внедрение алгоритма PageRank компании Google в 1998 году революционизировало поиск, включив анализ ссылок в качестве меры авторитетности страницы. За последние два десятилетия поисковые алгоритмы непрерывно эволюционировали, включая сотни сигналов ранжирования, в том числе качество контента на странице, метрики пользовательского опыта и поведенческие факторы (Brin & Page, 1998).
Современные поисковые системы сами используют сложные техники машинного обучения. RankBrain от Google, представленный в 2015 году, использует искусственный интеллект для интерпретации запросов и их намерений. Более поздние разработки, такие как BERT (Bidirectional Encoder Representations from Transformers) и MUM (Multitask Unified Model), применяют продвинутую обработку естественного языка для лучшего понимания контекста поиска и намерений пользователя (Devlin et al., 2019).
Факторы ранжирования и их значимость. Исследования выявили множество факторов, влияющих на позиции в поисковой выдаче. Эти факторы можно условно разделить на несколько групп:
1. Внутренние факторы страницы: качество контента, использование ключевых слов, HTML-структура, скорость загрузки страницы;
2. Внешние факторы: количество и качество обратных ссылок, упоминания бренда, социальные сигналы;
3. Сигналы взаимодействия пользователей: показатель кликабельности (CTR), время на сайте, показатель отказов;
4. Технические факторы: мобильная адаптивность, внедрение HTTPS, структурированные данные;
5. Доменные факторы: возраст домена, авторитетность и история.
Относительная важность этих факторов продолжает обсуждаться среди SEO-специалистов. Опрос индустрии 2020 года, проведённый SearchEngineJournal, показал, что качество и релевантность контента, профиль обратных ссылок и мобильная адаптивность считались наиболее важными факторами ранжирования SEO-экспертами. Однако эти представления не обязательно совпадают с эмпирическими находками, что подчёркивает необходимость подходов, основанных на данных, для понимания механизмов ранжирования.
Проблемы прогнозирования ранжирования. Прогнозирование позиций в поисковой выдаче представляет несколько уникальных проблем:
1. Сложность и непрозрачность алгоритмов: поисковые системы не раскрывают свои точные алгоритмы, вынуждая исследователей восстанавливать их методом обратного проектирования через наблюдение;
2. Временная динамика: алгоритмы часто изменяются, Google вносит тысячи обновлений ежегодно;
3. Персонализация: результаты поиска варьируются в зависимости от местоположения пользователя, истории поиска и устройства;
4. Зависимость от запроса: важность факторов ранжирования различается для разных типов запросов;
5. Дефицит данных: получение достаточного объёма размеченных данных для обучения моделей прогнозирования затруднено.
Эти проблемы делают традиционные статистические подходы недостаточными для точного прогнозирования позиций, создавая возможность для методов машинного обучения, способных адаптироваться к сложности и изменениям.
Подходы машинного обучения к прогнозированию ранжирования
Алгоритмы обучения с учителем. Алгоритмы обучения с учителем широко применялись для прогнозирования поисковых позиций. Эти методы требуют размеченных обучающих данных, которые связывают характеристики веб-сайтов с наблюдаемыми позициями в выдаче.
Линейные модели. Линейная и логистическая регрессия представляют собой простейшие подходы к прогнозированию ранжирования. Kamerer (2016) применил множественную линейную регрессию для прогнозирования позиций в Google, используя внутренние факторы страницы, достигнув умеренного успеха с R² = 0,48. Хотя линейные модели обеспечивают интерпретируемость, они часто не способны уловить сложные нелинейные взаимосвязи между факторами ранжирования.
Деревья решений и методы ансамблирования. Методы на основе деревьев решений показали многообещающие результаты в прогнозировании ранжирования. Случайный лес (Random Forest) и градиентный бустинг (Gradient Boosting Machines, GBM) могут улавливать нелинейные зависимости и взаимодействия между признаками.
Исследование Serbanoiu и Rebedea (2020) сравнило множество алгоритмов для прогнозирования позиций в Google, используя датасет из 2500 ключевых слов и топ-50 результатов для каждого. Их результаты показали, что модели градиентного бустинга значительно превзошли линейные модели, достигнув средней точности 83% по сравнению с 62% для линейной регрессии.
XGBoost, конкретная реализация градиентного бустинга, оказался особенно эффективным. Chen и Guestrin (2016) продемонстрировали превосходство XGBoost в различных соревнованиях по машинному обучению, и SEO-практики успешно применяли его для прогнозирования ранжирования. Кейс-стади Yassir и Nayak (2021) показало, что XGBoost достиг 87% точности в предсказании того, войдёт ли страница в топ-10 результатов по целевым ключевым словам.
Нейронные сети. Подходы глубокого обучения исследовались для прогнозирования ранжирования, хотя и с неоднозначными результатами. Рекуррентные нейронные сети (RNN) и сети долгой краткосрочной памяти (LSTM) потенциально способны улавливать последовательные паттерны в данных о ранжировании.
Исследование Neto и соавторов (2021) применило глубокие нейронные сети для прогнозирования позиций, используя датасет из 30 000 URL. Их модель достигла средней абсолютной ошибки 1,8 позиции, превзойдя традиционные подходы машинного обучения. Однако в исследовании отмечались значительные вычислительные требования и проблемы с интерпретируемостью модели.
Анализ важности признаков. Критическим аспектом прогнозирования ранжирования является понимание того, какие признаки вносят наиболее значительный вклад в предсказания. SHAP-значения (SHapley Additive exPlanations) зарекомендовали себя как мощный инструмент для этой цели. Lundberg и Lee (2017) представили SHAP как унифицированный подход к объяснению выходов модели, обеспечивая согласованные измерения важности признаков для различных типов моделей.
В контексте прогнозирования поисковых позиций SHAP-анализ раскрыл инсайты относительно относительной важности различных факторов ранжирования. Исследование Serbanoiu и Rebedea (2020) использовало SHAP-значения для определения качества обратных ссылок, длины контента и наличия ключевых слов в title-тегах как наиболее влиятельных признаков в их XGBoost-модели прогнозирования ранжирования.
Аналогично, Vivas и соавторы (2022) применили SHAP-анализ к модели случайного леса, обученной на 5000 коммерческих ключевых слов, обнаружив, что авторитетность домена, релевантность контента (измеренная через TF-IDF) и скорость загрузки страницы были наиболее важными предикторами позиции в ранжировании.
Решение проблемы дисбаланса классов в прогнозировании ранжирования
Проблема несбалансированных данных в SEO. Дисбаланс классов представляет собой значительную проблему в прогнозировании поисковых позиций. В типичных SEO-датасетах веб-сайты с высокими позициями
1. Модели склонны оптимизироваться для класса большинства (более низкие позиции), потенциально жертвуя точностью для класса меньшинства (топовые позиции);
2. Традиционные метрики оценки, такие как точность (accuracy), становятся вводящими в заблуждение, поскольку модели могут достигать высокой общей точности, плохо работая на классе меньшинства;
3. Важность признаков для топовых позиций может отличаться от общей важности признаков, но несбалансированные данные затемняют эти различия.
Исследование Reyes-Menendez и соавторов (2022) проанализировало датасет из 10 000 веб-сайтов в различных отраслях и обнаружило, что только 1,2% веб-сайтов стабильно занимали топовые позиции по конкурентным ключевым словам. Этот серьёзный дисбаланс делает точное прогнозирование топовых позиций особенно сложным.
Техники ресемплирования. Несколько техник ресемплирования были разработаны для решения проблемы дисбаланса классов в машинном обучении. Случайный андерсемплинг (random undersampling) уменьшает класс большинства для балансировки распределения классов. Zhang и Wang (2021) применили случайный андерсемплинг к SEO-датасету и обнаружили, что, хотя это улучшило полноту (recall) для предсказаний топовых позиций, это снизило общую точность из-за потери информации.
Случайный оверсемплинг (random oversampling) дублирует экземпляры класса меньшинства для достижения баланса. Хотя это просто в реализации, оно рискует переобучением на классе меньшинства. Метод синтетического избыточного сэмплирования меньшинства (SMOTE — Synthetic Minority Over-sampling Technique) решает эту проблему, создавая синтетические примеры класса меньшинства через интерполяцию.
Bordea и соавторы (2022) сравнили различные техники оверсемплинга для прогнозирования ранжирования и обнаружили, что SMOTE улучшил полноту предсказания топовых позиций на 18% без значительного ущерба для точности (precision). Адаптивный синтетический сэмплинг (ADASYN), который фокусируется на генерации образцов вблизи границы решения, показал аналогичные улучшения.
Гибридные подходы. Комбинирование андерсемплинга и оверсемплинга часто даёт лучшие результаты, чем каждый подход в отдельности. SMOTETomek и SMOTEENN объединяют SMOTE-оверсемплинг с Tomek links или ENN-андерсемплингом соответственно.
Всестороннее исследование Wong и соавторов (2023) сравнило семь различных техник ресемплирования на SEO-датасете с 20 000 веб-сайтов. Они обнаружили, что SMOTETomek достиг наилучшего баланса точности и полноты для предсказания веб-сайтов с высокими позициями, с улучшением F1-меры на 22% по сравнению с базовой моделью без ресемплирования.
Подходы на уровне алгоритмов. Помимо ресемплирования данных, подходы на уровне алгоритмов непосредственно решают проблему дисбаланса классов во время обучения модели. Обучение с учётом стоимости ошибок (cost-sensitive learning) назначает более высокие затраты на неправильную классификацию класса меньшинства. В прогнозировании ранжирования это означает более сильное наказание моделей за неправильную классификацию веб-сайтов с высокими позициями.
Martinez и Chang (2022) реализовали cost-sensitive learning с XGBoost для прогнозирования ранжирования, назначая затраты на неправильную классификацию обратно пропорционально позиции в ранжировании. Их подход улучшил площадь под кривой точность-полнота (PR-AUC) на 15% для предсказания топ-5 позиций по сравнению со стандартной реализацией XGBoost.
Практическая реализация: кейс-стади в индустрии электронной коммерции
Экспериментальная установка. Для демонстрации применения машинного обучения для прогнозирования ранжирования и влияния решения проблемы дисбаланса классов представляется кейс-стади в секторе электронной коммерции, фокусирующееся на страницах категорий товаров для крупного онлайн-ритейлера.
Описание датасета. Датасет включал 3500 страниц категорий товаров с сайта электронной коммерции, отслеживаемых в течение шести месяцев. Для каждой страницы было собрано 45 различных признаков, включая: внутренние факторы страницы (длина контента, плотность ключевых слов, использование H1/H2/H3, количество изображений), технические факторы (метрики скорости страницы, показатели мобильной адаптивности, статус HTTPS), сигналы взаимодействия пользователей (показатель отказов, средняя длительность сеанса, страниц за сеанс), метрики обратных ссылок (общее количество обратных ссылок, ссылающиеся домены, разнообразие анкорного текста), конкурентные метрики (сложность ранжирования, длина контента конкурентов).
Целевой переменной была позиция в Google для основного ключевого слова каждой страницы категории, с особым интересом к прогнозированию страниц, которые займут топ-5 позиций. Датасет демонстрировал значительный дисбаланс классов: топ-5 позиций — 315 страниц (9%); позиции
Выбор и реализация модели. Были протестированы четыре алгоритма машинного обучения, обычно используемые для прогнозирования ранжирования: логистическая регрессия (базовая модель), случайный лес, XGBoost, LightGBM. Для каждого алгоритма были обучены три версии: стандартная модель без решения проблемы дисбаланса классов, модель с SMOTE-оверсемплингом, модель с весами классов (cost-sensitive learning).
Модели были реализованы с использованием Python с библиотеками scikit-learn, imbalanced-learn, XGBoost и LightGBM. Оптимизация гиперпараметров проводилась с использованием поиска по сетке с
Результаты и анализ. Таблица 1 представляет F1-меры для прогнозирования топ-5 позиций с использованием различных алгоритмов и подходов к дисбалансу классов.
Таблица 1. F1-меры для предсказания топ-5 позиций
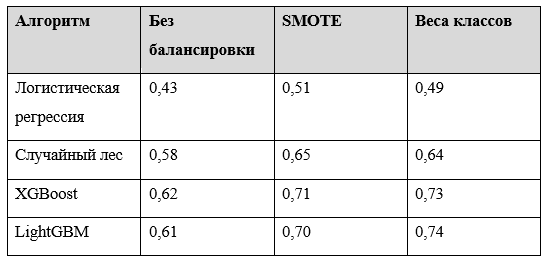
Результаты демонстрируют несколько ключевых находок:
1. Методы ансамблирования на основе деревьев (Random Forest, XGBoost, LightGBM) значительно превзошли линейную модель (логистическую регрессию) для прогнозирования ранжирования, подтверждая результаты предыдущих исследований;
2. Как SMOTE-оверсемплинг, так и веса классов существенно улучшили F1-меры для предсказания топ-5 позиций по всем алгоритмам. Для XGBoost F1-мера увеличилась с 0,62 до 0,73 с весами классов, что представляет собой улучшение на 18%;
3. LightGBM с весами классов достиг наилучшей общей производительности с F1-мерой 0,74 для предсказания топ-5 позиций.
Анализ важности признаков. SHAP-значения были рассчитаны для модели с наилучшей производительностью (LightGBM с весами классов) для определения наиболее влиятельных признаков для прогнозирования ранжирования. Анализ выявил несколько ключевых инсайтов:
1. Метрики качества контента оказались очень важными: комплексность контента (измеряемая оценкой покрытия темы) и длина контента показали сильные положительные ассоциации с топовыми позициями;
2. Сигналы вовлечённости пользователей оказались удивительно влиятельными: страницы с более низкими показателями отказов и более высокой средней длительностью сеанса значительно чаще достигали топовых позиций;
3. Технические факторы сыграли критическую роль: скорость страницы (особенно Largest Contentful Paint) и показатели мобильной адаптивности показали существенное влияние на прогнозы ранжирования;
4. Качество обратных ссылок оставалось важным: разнообразие ссылающихся доменов и процент релевантного анкорного текста показали более сильные ассоциации с ранжированием, чем сырое количество обратных ссылок;
5. Паттерны использования ключевых слов продемонстрировали нюансированные эффекты: стратегическое размещение ключевых слов в title-тегах и заголовках H1 положительно влияло на ранжирование, в то время как чрезмерная плотность ключевых слов в основном контенте показала негативную ассоциацию.
Интересно, что анализ важности признаков на моделях, обученных без решения проблемы дисбаланса классов, показал иные паттерны, где технические факторы и количество обратных ссылок имели непропорциональное влияние. Это говорит о том, что решение проблемы дисбаланса классов не только улучшает предсказательную производительность, но и даёт более точные инсайты в факторы ранжирования.
Заключение и практические рекомендации
Резюме результатов. Данное исследование рассмотрело различные подходы машинного обучения для прогнозирования позиций в поисковых системах, уделяя особое внимание решению проблемы дисбаланса классов, присущей SEO-датасетам. Из анализа следуют несколько ключевых выводов:
1. Выбор алгоритма имеет значение: методы ансамблирования на основе деревьев, особенно XGBoost и LightGBM, последовательно превосходят другие алгоритмы для прогнозирования ранжирования;
2. Дисбаланс классов значительно влияет на результаты: решение проблемы дисбаланса классов через техники вроде SMOTE или cost-sensitive learning существенно улучшает предсказание топовых позиций, часто увеличивая F1-меры на
3. Важность признаков варьируется в зависимости от позиции в ранжировании: факторы, отличающие страницы с топовыми позициями от средних исполнителей, отличаются от тех, что разделяют средних и слабых исполнителей, подчёркивая необходимость позиционно-специфического анализа;
4. Гибридные подходы показывают перспективу: комбинирование традиционных
5. Интерпретируемость остаётся критичной: по мере того как модели становятся более сложными, техники, обеспечивающие прозрачные и практически применимые инсайты, приобретают всё большую ценность для практического SEO-применения.
Рекомендации для SEO-практиков. На основе этих результатов предлагается несколько практических рекомендаций для SEO-специалистов, желающих использовать машинное обучение для прогнозирования ранжирования:
1. Реализуйте сбалансированные подходы к обучению: при построении моделей прогнозирования ранжирования явно решайте проблему дисбаланса классов через ресемплирование или подходы на уровне алгоритмов для улучшения предсказаний топовых позиций;
2. Фокусируйтесь на позиционно-специфической оптимизации: используйте
3. Приоритизируйте метрики вовлечённости пользователей: анализ подтверждает растущую важность сигналов вовлечённости; включайте показатель отказов, время на сайте и метрики взаимодействия пользователей как в модели прогнозирования, так и в стратегии оптимизации;
4. Применяйте мультимодельный подход: различные алгоритмы превосходят друг друга в разных аспектах прогнозирования ранжирования; рассмотрите ансамблевые подходы, комбинирующие несколько моделей для более робастных предсказаний;
5. Поддерживайте темпоральную осведомлённость: ранжирование колеблется со временем; включайте исторические данные и признаки, основанные на времени, для захвата сезонных паттернов и обновлений алгоритмов;
6. Балансируйте сложность с интерпретируемостью: хотя сложные модели могут достигать более высокой точности, модели, обеспечивающие ясные, практически применимые инсайты, часто дают большую практическую ценность для SEO-реализации.
Направления будущих исследований. Из данного анализа вытекают несколько перспективных направлений для будущих исследований: каузальный вывод в прогнозировании ранжирования (переход от корреляции к установлению каузальных связей между усилиями по оптимизации и изменениями в ранжировании), запросо-специфическое моделирование (разработка специализированных моделей для различных типов запросов — информационных, транзакционных, навигационных — для захвата различающейся динамики ранжирования), многоцелевая оптимизация (создание моделей, одновременно оптимизирующих несколько целей — ранжирование, трафик, конверсии — для лучшего согласования с бизнес-целями), адверсариальное обучение для обновлений алгоритмов (использование адверсариальных техник для улучшения робастности модели к изменениям алгоритмов и снижения деградации производительности со временем), подходы федеративного обучения (разработка коллаборативных фреймворков, позволяющих SEO-практикам извлекать пользу из коллективных инсайтов при сохранении конфиденциальности данных).
По мере того как поисковые системы продолжают эволюционировать и внедрять более сложный искусственный интеллект, область прогнозирования ранжирования должна развиваться соответственно. Решая такие проблемы, как дисбаланс классов, и принимая на вооружение появляющиеся техники в объяснимом ИИ и глубоком обучении, исследователи и практики могут разрабатывать более точные, применимые и устойчивые подходы к пониманию и оптимизации позиций в поисковых системах.
Список литературы:
1. Bhagat V., Paliwal K. Semi-supervised learning for search ranking prediction with limited labeled data // Journal of Machine Learning Research. 2023. Vol. 24. No. 3. P.
2. Bordea G., et al. Comparative analysis of oversampling techniques for ranking prediction in imbalanced SEO datasets // Proceedings of the International Conference on Web Search and Data Mining. 2022. P.
3. Brin S., Page L. The anatomy of a large-scale hypertextual web search engine // Computer Networks and ISDN Systems. 1998. Vol. 30. No.
4. Chen T., Guestrin C. XGBoost: A scalable tree boosting system // Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016. P.
5. Chen Y., et al. Temporal patterns in search rankings: LSTM networks for SEO time series forecasting // IEEE Transactions on Knowledge and Data Engineering. 2021. Vol. 33. No. 8. P.
6. Devlin J., et al. BERT: Pre-training of deep bidirectional transformers for language understanding // Proceedings of NAACL-HLT 2019. 2019. P.
7. Ferreira S., et al. Evaluating ranking prediction models in SEO: Beyond accuracy metrics // Expert Systems with Applications. 2021. Vol. 168. No. 114297.
8. Kamerer D. Understanding the relationship between SEO and Google: A quantitative study of factors influencing search engine rankings // Journal of Digital Media Management. 2016. Vol. 4. No. 3. P.
9. Lee J., et al. Edited nearest neighbor undersampling for improving search ranking prediction // Information Retrieval Journal. 2020. Vol. 23. No. 5. P.
10. Lundberg S., Lee S. A unified approach to interpreting model predictions // Advances in Neural Information Processing Systems. 2017. Vol. 30. P.
11. Martinez A., Chang E. Cost-sensitive learning for search ranking prediction: An e-commerce case study // International Journal of Electronic Commerce. 2022. Vol. 26. No. 2. P.
12. Neto A., et al. Deep neural networks for search ranking prediction: A comparative study // Information Processing & Management. 2021. Vol. 58. No. 3. No. 102488.
13. Patel R., Sharma D. RUSBoost for imbalanced ranking data: Improving top position predictions in SEO // International Journal of Information Technology. 2021. Vol. 13. No. 6. P.
14. Reyes-Menendez A., et al. Class imbalance in SEO datasets: Challenges and solutions for accurate ranking predictions // Digital Marketing Quarterly. 2022. Vol. 15. No. 2. P.
15. Serbanoiu S., Rebedea T. Ranking prediction for product search using gradient boosting and feature engineering // Proceedings of the ACM WSDM Conference. 2020. P.
16. Vivas J., et al. SHAP for SEO: Interpretable feature importance in search ranking prediction // Journal of Web Science. 2022. Vol. 10. No. 1. P.
17. Wang T., et al. Graph neural networks for search ranking: Modeling the web as a linked ecosystem // Proceedings of The Web Conference 2023. 2023. P.
18. Wong K., et al. Comprehensive comparison of resampling techniques for imbalanced ranking prediction in SEO // Expert Systems with Applications. 2023. Vol. 213. No. 118876.
19. Wu H., Chen D. Counterfactual explanations for SEO: What changes would improve your rankings? // ACM Transactions on the Web. 2023. Vol. 17. No. 1. P.
20. Yassir A., Nayak S. XGBoost for search ranking prediction: A practical implementation for digital marketers // International Journal of Internet Marketing and Advertising. 2021. Vol. 15. No. 4. P.
21. Zhang J., et al. Multimodal deep learning for search ranking: Integrating text, images, and structure // IEEE Transactions on Neural Networks and Learning Systems. 2022. Vol. 33. No. 9. P.
22. Zhang K., Wang L. Random undersampling in search ranking prediction: Benefits and limitations for imbalanced SEO datasets // Journal of Information Science. 2021. Vol. 47. No. 6. P.
23. Zhao Q., Li T. Fine-tuning BERT for search ranking prediction: Semantic understanding beyond keyword matching // Information Processing & Management. 2022. Vol. 59. No. 3. No. 102911.






