–љ–∞—Г—З–љ—Л–є
–ґ—Г—А–љ–∞–ї
–°—А–Њ—З–љ–∞—П –њ—Г–±–ї–Є–Ї–∞—Ж–Є—П –љ–∞—Г—З–љ–Њ–є —Б—В–∞—В—М–Є
+7 995 770 98 40
+7 995 202 54 42
info@journalpro.ru

–Ы–Њ–Ї–∞–ї—М–љ—Л–є inference –Ї—А—Г–њ–љ—Л—Е —П–Ј—Л–Ї–Њ–≤—Л—Е –Љ–Њ–і–µ–ї–µ–є: –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М, –њ–∞–Љ—П—В—М –Є –њ—А–Є–Љ–µ–љ–Є–Љ–Њ—Б—В—М

–†—Г–±—А–Є–Ї–∞: –Ґ–µ—Е–љ–Є—З–µ—Б–Ї–Є–µ –љ–∞—Г–Ї–Є
–Ц—Г—А–љ–∞–ї: «–Х–≤—А–∞–Ј–Є–є—Б–Ї–Є–є –Э–∞—Г—З–љ—Л–є –Ц—Г—А–љ–∞–ї вДЦ5 2025» (–Љ–∞–є, 2025)
–Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ—А–Њ—Б–Љ–Њ—В—А–Њ–≤ —Б—В–∞—В—М–Є: 985
–Я–Њ–Ї–∞–Ј–∞—В—М PDF –≤–µ—А—Б–Є—О –Ы–Њ–Ї–∞–ї—М–љ—Л–є inference –Ї—А—Г–њ–љ—Л—Е —П–Ј—Л–Ї–Њ–≤—Л—Е –Љ–Њ–і–µ–ї–µ–є: –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М, –њ–∞–Љ—П—В—М –Є –њ—А–Є–Љ–µ–љ–Є–Љ–Њ—Б—В—М
–Э–Є—П–Ј–Њ–≤–∞ –С–∞—А–љ–Њ–љ–Є—Б–Њ –Э–∞–Є–Љ–і–ґ–Њ–љ–Њ–≤–љ–∞
–∞—Б–њ–Є—А–∞–љ—В 4 –Ї—Г—А—Б–∞,
–†–Њ—Б—Б–Є–є—Б–Ї–Є–є –≥–Њ—Б—Г–і–∞—А—Б—В–≤–µ–љ–љ—Л–є —Г–љ–Є–≤–µ—А—Б–Є—В–µ—В –Є–Љ–µ–љ–Є –Ъ–Њ—Б—Л–≥–Є–љ–∞,
–≥. –Ь–Њ—Б–Ї–≤–∞
–Р–љ–љ–Њ—В–∞—Ж–Є—П: –¶–µ–ї—М –і–∞–љ–љ–Њ–є —Б—В–∞—В—М–Є вАФ –њ—А–Њ–≤–µ—Б—В–Є —Б—А–∞–≤–љ–Є—В–µ–ї—М–љ—Л–є –∞–љ–∞–ї–Є–Ј –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –ї–Њ–Ї–∞–ї—М–љ–Њ–≥–Њ –Є–љ—Д–µ—А–µ–љ—Б–∞ –Ї—А—Г–њ–љ—Л—Е —П–Ј—Л–Ї–Њ–≤—Л—Е –Љ–Њ–і–µ–ї–µ–є, –Њ—Ж–µ–љ–Є—В—М –Є—Е –њ—А–Є–Љ–µ–љ–Є–Љ–Њ—Б—В—М –≤ –Ј–∞–і–∞—З–∞—Е –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Њ–≥–Њ –Є–љ—В–µ—А—Д–µ–є—Б–∞ (UI) –Є –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–≥–Њ —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П, –∞ —В–∞–Ї–ґ–µ —Б—Д–Њ—А–Љ—Г–ї–Є—А–Њ–≤–∞—В—М —А–µ–Ї–Њ–Љ–µ–љ–і–∞—Ж–Є–Є –њ–Њ –≤—Л–±–Њ—А—Г –∞—А—Е–Є—В–µ–Ї—В—Г—А –і–ї—П –Ј–∞–њ—Г—Б–Ї–∞ –±–µ–Ј –њ–Њ–і–Ї–ї—О—З–µ–љ–Є—П –Ї –≤–љ–µ—И–љ–Є–Љ API. –Т –Њ—Б–љ–Њ–≤–µ –∞–љ–∞–ї–Є–Ј–∞ –ї–µ–ґ–Є—В –Њ–њ—Л—В –Є–љ—В–µ–≥—А–∞—Ж–Є–Є –Љ–Њ–і–µ–ї–Є DeepSeek-R1 –≤ —Б–Є—Б—В–µ–Љ—Г –≥–µ–љ–µ—А–∞—Ж–Є–Є —В–µ—Б—В-–Ї–µ–є—Б–Њ–≤ UI/API –љ–∞ –±–∞–Ј–µ Playwright, —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ —Б—А–µ–і—Л MacBook –љ–∞ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–µ Apple M1 —Б –њ–Њ–і–і–µ—А–ґ–Ї–Њ–є Metal Performance Shaders (MPS).
–Ъ–ї—О—З–µ–≤—Л–µ —Б–ї–Њ–≤–∞: —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–µ, –Є–љ—Б—В—А—Г–Љ–µ–љ—В—Л —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П, –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Њ–љ–љ—Л–µ —В–µ—Е–љ–Њ–ї–Њ–≥–Є–Є, –≤–µ–±-–њ—А–Є–ї–Њ–ґ–µ–љ–Є—П.
–Т –њ–Њ—Б–ї–µ–і–љ–Є–µ –≥–Њ–і—Л –Ї—А—Г–њ–љ—Л–µ —П–Ј—Л–Ї–Њ–≤—Л–µ –Љ–Њ–і–µ–ї–Є (Large Language Models, LLMs) —Б—В–∞–ї–Є –Ї—А–∞–µ—Г–≥–Њ–ї—М–љ—Л–Љ –Ї–∞–Љ–љ–µ–Љ —Б–Њ–≤—А–µ–Љ–µ–љ–љ—Л—Е —Б–Є—Б—В–µ–Љ –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–≥–Њ –Є–љ—В–µ–ї–ї–µ–Ї—В–∞. –Ґ–∞–Ї–Є–µ –Љ–Њ–і–µ–ї–Є, –Ї–∞–Ї GPT-4, LLaMA, DeepSeek –Є –Є—Е –њ—А–Њ–Є–Ј–≤–Њ–і–љ—Л–µ, –і–µ–Љ–Њ–љ—Б—В—А–Є—А—Г—О—В –≤—Л—Б–Њ–Ї—Г—О —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ—Б—В—М –≤ –Ј–∞–і–∞—З–∞—Е –≥–µ–љ–µ—А–∞—Ж–Є–Є, –∞–љ–∞–ї–Є–Ј–∞ —В–µ–Ї—Б—В–∞, –њ—А–Њ–≥—А–∞–Љ–Љ–Є—А–Њ–≤–∞–љ–Є—П –Є –і–∞–ґ–µ –њ—А–Є–љ—П—В–Є—П —А–µ—И–µ–љ–Є–є. –Ю–і–љ–∞–Ї–Њ —И–Є—А–Њ–Ї–Њ–µ —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ–µ–љ–Є–µ LLM —Б–Њ–њ—А—П–ґ–µ–љ–Њ —Б —А—П–і–Њ–Љ –≤—Л–Ј–Њ–≤–Њ–≤, —Б—А–µ–і–Є –Ї–Њ—В–Њ—А—Л—Е –Ї–ї—О—З–µ–≤—Л–Љ–Є —П–≤–ї—П—О—В—Б—П: –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М –њ—А–Є –ї–Њ–Ї–∞–ї—М–љ–Њ–Љ –Ј–∞–њ—Г—Б–Ї–µ, —В—А–µ–±–Њ–≤–∞–љ–Є—П –Ї –∞–њ–њ–∞—А–∞—В–љ—Л–Љ —А–µ—Б—Г—А—Б–∞–Љ, –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П –њ–∞–Љ—П—В–Є –Є –њ—А–Є–Љ–µ–љ–Є–Љ–Њ—Б—В—М –≤ –њ—А–Є–Ї–ї–∞–і–љ—Л—Е –Ј–∞–і–∞—З–∞—Е.
–Ю–±–Ј–Њ—А –∞—А—Е–Є—В–µ–Ї—В—Г—А –Є —В—А–µ–±–Њ–≤–∞–љ–Є–є
–°–Њ–≤—А–µ–Љ–µ–љ–љ—Л–µ —П–Ј—Л–Ї–Њ–≤—Л–µ –Љ–Њ–і–µ–ї–Є –Њ—В–ї–Є—З–∞—О—В—Б—П –њ–Њ —Б–ї–µ–і—Г—О—Й–Є–Љ –њ–∞—А–∞–Љ–µ—В—А–∞–Љ:
вАФ –Ю–±—К—С–Љ –Љ–Њ–і–µ–ї–Є (—З–Є—Б–ї–Њ –њ–∞—А–∞–Љ–µ—В—А–Њ–≤): –Њ—В 1B –і–Њ 70B+
вАФ –§–Њ—А–Љ–∞—В –Ј–∞–≥—А—Г–Ј–Ї–Є (FP32, BF16, INT4/8)
вАФ –Ь–∞–Ї—Б–Є–Љ–∞–ї—М–љ–∞—П –і–ї–Є–љ–∞ –Ї–Њ–љ—В–µ–Ї—Б—В–∞
вАФ –Р—А—Е–Є—В–µ–Ї—В—Г—А–∞: Dense vs MoE (Mixture of Experts)
вАФ –Я–Њ–і–і–µ—А–ґ–Ї–∞ MPS, CUDA, ROCm, CPU
–Ґ–∞–±–ї–Є—Ж–∞ 1. –°—А–∞–≤–љ–µ–љ–Є–µ –Љ–Њ–і–µ–ї–µ–є –њ–Њ —В—А–µ–±–Њ–≤–∞–љ–Є—П–Љ
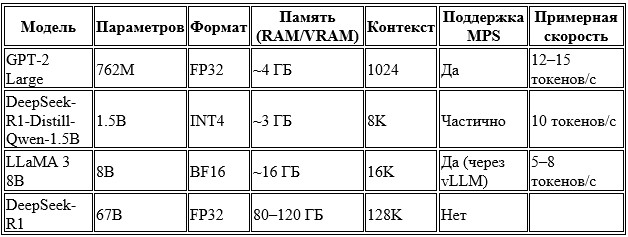
–Ь–µ—В–Њ–і–Є–Ї–∞ –Њ—Ж–µ–љ–Ї–Є
–Ф–ї—П –Њ—Ж–µ–љ–Ї–Є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –Є–љ—Д–µ—А–µ–љ—Б–∞ –±—Л–ї–∞ —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ–∞ —Б–Є—Б—В–µ–Љ–∞ –≥–µ–љ–µ—А–∞—Ж–Є–Є —И–∞–≥–Њ–≤ —В–µ—Б—В-–Ї–µ–є—Б–Њ–≤ —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ LLM. –Р—А—Е–Є—В–µ–Ї—В—Г—А–∞ –≤–Ї–ї—О—З–∞–µ—В:
вАФ Frontend (HTML) –Є–љ—В–µ—А—Д–µ–є—Б –і–ї—П –Њ—В–Њ–±—А–∞–ґ–µ–љ–Є—П –њ–ї–∞–љ–∞ —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П
вАФ Backend –љ–∞ FastAPI —Б –Љ–∞—А—И—А—Г—В–Њ–Љ /generate-plan, –Њ–±—А–∞–±–∞—В—Л–≤–∞—О—Й–Є–Љ URL
вАФ –Ь–Њ–і—Г–ї—М –≥–µ–љ–µ—А–∞—Ж–Є–Є generate_with_deepseek(prompt: str) –і–ї—П –Њ–±—А–∞—Й–µ–љ–Є—П –Ї –Љ–Њ–і–µ–ї–Є
вАФ –Т—Л–≤–Њ–і —А–µ–Ј—Г–ї—М—В–∞—В–Њ–≤ –≤ PDF/Excel –Є –≤ UI
–†–µ–Ј—Г–ї—М—В–∞—В—Л —Н–Ї—Б–њ–µ—А–Є–Љ–µ–љ—В–Њ–≤
–≠–Ї—Б–њ–µ—А–Є–Љ–µ–љ—В—Л –њ—А–Њ–≤–Њ–і–Є–ї–Є—Б—М –љ–∞ MacBook Pro —Б M1 Pro (32 –У–С RAM). –Т –Ї–∞—З–µ—Б—В–≤–µ –Љ–Њ–і–µ–ї–Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї—Б—П DeepSeek-R1-Distill-Qwen-1.5B, –Ј–∞–≥—А—Г–ґ–µ–љ–љ—Л–є —З–µ—А–µ–Ј transformers –Є AutoModelForCausalLM.
–Ґ–∞–±–ї–Є—Ж–∞ 2. –°—А–∞–≤–љ–µ–љ–Є–µ —А–µ–ґ–Є–Љ–Њ–≤

–Я—А–Є–Љ–µ—А –Ј–∞–њ—А–Њ—Б–∞ –Є –≥–µ–љ–µ—А–∞—Ж–Є–Є
Prompt: ¬Ђ–Э–∞–њ–Є—И–Є –њ–Њ–і—А–Њ–±–љ—Л–µ —И–∞–≥–Є –Є –Њ–ґ–Є–і–∞–љ–Є—П –і–ї—П —В–µ—Б—В–∞ –љ–∞ –њ—А–Њ–≤–µ—А–Ї—Г –Ї–ї–Є–Ї–∞ –њ–Њ —Б—Б—Л–ї–Ї–µ —Б —В–µ–Ї—Б—В–Њ–Љ: вАШ–Ъ–Њ–љ—В–∞–Ї—В—ЛвАЩ¬ї
–Ю—В–≤–µ—В (—Б–≥–µ–љ–µ—А–Є—А–Њ–≤–∞–љ–Њ –ї–Њ–Ї–∞–ї—М–љ–Њ):
–®–∞–≥ 1 вАФ –Њ—В–Ї—А—Л—В—М –≥–ї–∞–≤–љ—Г—О —Б—В—А–∞–љ–Є—Ж—Г —Б–∞–є—В–∞
–®–∞–≥ 2 вАФ –љ–∞–є—В–Є —Н–ї–µ–Љ–µ–љ—В ¬Ђ–Ъ–Њ–љ—В–∞–Ї—В—Л¬ї
–®–∞–≥ 3 вАФ –Ї–ї–Є–Ї–љ—Г—В—М –њ–Њ —Н–ї–µ–Љ–µ–љ—В—Г
–®–∞–≥ 4 вАФ –њ—А–Њ–≤–µ—А–Є—В—М, —З—В–Њ URL –Є–Ј–Љ–µ–љ–Є–ї—Б—П –љ–∞ ¬Ђ/contacts¬ї
–®–∞–≥ 5 вАФ —Г–±–µ–і–Є—В—М—Б—П, —З—В–Њ –Њ—В–Њ–±—А–∞–ґ–∞–µ—В—Б—П –Ј–∞–≥–Њ–ї–Њ–≤–Њ–Ї ¬Ђ–Ъ–Њ–љ—В–∞–Ї—В—Л¬ї
–Ю–ґ–Є–і–∞–љ–Є–µ: –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М –і–Њ–ї–ґ–µ–љ —Г–≤–Є–і–µ—В—М —Б—В—А–∞–љ–Є—Ж—Г —Б –Ї–Њ–љ—В–∞–Ї—В–љ–Њ–є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–µ–є
–Р–љ–∞–ї–Є–Ј –њ—А–Є–Љ–µ–љ–Є–Љ–Њ—Б—В–Є –Є –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–є
–Ъ–Њ–≥–і–∞ –ї–Њ–Ї–∞–ї—М–љ—Л–є –Ј–∞–њ—Г—Б–Ї –Њ–њ—А–∞–≤–і–∞–љ
–Ы–Њ–Ї–∞–ї—М–љ—Л–є –Є–љ—Д–µ—А–µ–љ—Б –Ї—А—Г–њ–љ—Л—Е —П–Ј—Л–Ї–Њ–≤—Л—Е –Љ–Њ–і–µ–ї–µ–є —Б—В–∞–љ–Њ–≤–Є—В—Б—П –Њ—Б–Њ–±–µ–љ–љ–Њ –∞–Ї—В—Г–∞–ї–µ–љ –≤ —Б–ї–µ–і—Г—О—Й–Є—Е —Б–ї—Г—З–∞—П—Е:
1. –Ю–≥—А–∞–љ–Є—З–µ–љ–Є–µ –і–Њ—Б—В—Г–њ–∞ –Ї API: –љ–∞–њ—А–Є–Љ–µ—А, –њ—А–Є —А–∞–Ј—А–∞–±–Њ—В–Ї–µ –≤ —Г—Б–ї–Њ–≤–Є—П—Е, –Ї–Њ–≥–і–∞ HuggingFace –Є–ї–Є OpenAI API –љ–µ–і–Њ—Б—В—Г–њ–љ—Л –Є–Ј-–Ј–∞ –≥–µ–Њ–≥—А–∞—Д–Є—З–µ—Б–Ї–Є—Е –Є–ї–Є —Б–µ—В–µ–≤—Л—Е –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–є.
2. –°–љ–Є–ґ–µ–љ–Є–µ –Ј–∞—В—А–∞—В: –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Њ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ API –≤ –≤—Л—Б–Њ–Ї–Њ–љ–∞–≥—А—Г–ґ–µ–љ–љ—Л—Е —Б–Є—Б—В–µ–Љ–∞—Е –Љ–Њ–ґ–µ—В –Њ–±—Е–Њ–і–Є—В—М—Б—П –≤ –і–µ—Б—П—В–Ї–Є —В—Л—Б—П—З —А—Г–±–ї–µ–є –≤ –Љ–µ—Б—П—Ж. –Ы–Њ–Ї–∞–ї—М–љ—Л–є –Ј–∞–њ—Г—Б–Ї (–µ–і–Є–љ–Њ–≤—А–µ–Љ–µ–љ–љ–∞—П –љ–∞—Б—В—А–Њ–є–Ї–∞ –Љ–Њ–і–µ–ї–Є –љ–∞ —Б–µ—А–≤–µ—А–µ –Є–ї–Є –љ–Њ—Г—В–±—Г–Ї–µ) –њ–Њ–Ј–≤–Њ–ї—П–µ—В —Б–Њ–Ї—А–∞—В–Є—В—М —А–∞—Б—Е–Њ–і—Л.
3. –Я–Њ–≤—Л—И–µ–љ–љ—Л–µ —В—А–µ–±–Њ–≤–∞–љ–Є—П –Ї –Ї–Њ–љ—Д–Є–і–µ–љ—Ж–Є–∞–ї—М–љ–Њ—Б—В–Є: –њ—А–Є –Њ–±—А–∞–±–Њ—В–Ї–µ —З—Г–≤—Б—В–≤–Є—В–µ–ї—М–љ—Л—Е –і–∞–љ–љ—Л—Е (–љ–∞–њ—А–Є–Љ–µ—А, –≥–µ–љ–µ—А–Є—А–Њ–≤–∞–љ–Є–µ —В–µ—Б—В–Њ–≤ –њ–Њ –≤–љ—Г—В—А–µ–љ–љ–Є–Љ CRM –Є–ї–Є HR-—Б–Є—Б—В–µ–Љ–∞–Љ) –ї–Њ–Ї–∞–ї—М–љ—Л–є –Ј–∞–њ—Г—Б–Ї –Є—Б–Ї–ї—О—З–∞–µ—В —Г—В–µ—З–Ї—Г –і–∞–љ–љ—Л—Е –љ–∞ –≤–љ–µ—И–љ–Є–µ —Б–µ—А–≤–µ—А–∞.
4. –Т–Њ—Б–њ—А–Њ–Є–Ј–≤–Њ–і–Є–Љ–Њ—Б—В—М —А–µ–Ј—Г–ї—М—В–∞—В–Њ–≤: –≤ —А—П–і–µ –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–є –≤–∞–ґ–љ–Њ —Б–Њ—Е—А–∞–љ—П—В—М –Ї–Њ–љ—В—А–Њ–ї—М –љ–∞–і –Љ–Њ–і–µ–ї—М—О, –≤–µ—А—Б–Є–µ–є, seed –Є –∞—А—Е–Є—В–µ–Ї—В—Г—А–Њ–є. –≠—В–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ —В–Њ–ї—М–Ї–Њ –њ—А–Є –ї–Њ–Ї–∞–ї—М–љ–Њ–Љ –Є–љ—Д–µ—А–µ–љ—Б–µ.
–Ю–≥—А–∞–љ–Є—З–µ–љ–Є—П –ї–Њ–Ї–∞–ї—М–љ–Њ–≥–Њ –Ј–∞–њ—Г—Б–Ї–∞
–Э–µ—Б–Љ–Њ—В—А—П –љ–∞ –њ–ї—О—Б—Л, –µ—Б—В—М –Є —А—П–і –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–є:
вАФ –Ч–∞–і–µ—А–ґ–Ї–∞ —Б—В–∞—А—В–∞ (cold start): –Ј–∞–њ—Г—Б–Ї –Љ–Њ–і–µ–ї–µ–є –Ј–∞–љ–Є–Љ–∞–µ—В –і–Њ 30 —Б–µ–Ї—Г–љ–і –≤ –Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–Є –Њ—В —А–∞–Ј–Љ–µ—А–∞ –Љ–Њ–і–µ–ї–Є –Є –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ VRAM.
вАФ –Я–Њ–і–і–µ—А–ґ–Ї–∞ –ґ–µ–ї–µ–Ј–∞: –і–∞–ґ–µ –њ—А–Є –љ–∞–ї–Є—З–Є–Є –њ–Њ–і–і–µ—А–ґ–Ї–Є Metal (MPS) –љ–∞ macOS, –љ–µ –≤—Б–µ –Љ–Њ–і–µ–ї–Є –Љ–Њ–≥—Г—В —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ —А–∞–±–Њ—В–∞—В—М. –Э–∞–њ—А–Є–Љ–µ—А, –љ–µ–Ї–Њ—В–Њ—А—Л–µ –∞—А—Е–Є—В–µ–Ї—В—Г—А—Л –љ–µ –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ—Л –њ–Њ–і M1/M2.
вАФ –Ю–≥—А–∞–љ–Є—З–µ–љ–Є—П –њ–Њ –і–ї–Є–љ–µ –Ї–Њ–љ—В–µ–Ї—Б—В–∞: –Љ–љ–Њ–≥–Є–µ –Љ–Њ–і–µ–ї–Є (–љ–∞–њ—А–Є–Љ–µ—А, GPT-2 –Є–ї–Є Qwen 1.5B) –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—О—В –Ї–Њ–љ—В–µ–Ї—Б—В —В–Њ–ї—М–Ї–Њ –і–Њ
–Т—Л–≤–Њ–і—Л
–Ы–Њ–Ї–∞–ї—М–љ—Л–є –Ј–∞–њ—Г—Б–Ї LLM –њ–Њ–Ј–≤–Њ–ї—П–µ—В —Б–Њ–Ј–і–∞—В—М –љ–µ–Ј–∞–≤–Є—Б–Є–Љ—Г—О, –∞–≤—В–Њ–љ–Њ–Љ–љ—Г—О —Б–Є—Б—В–µ–Љ—Г –≥–µ–љ–µ—А–∞—Ж–Є–Є –Є –≤–∞–ї–Є–і–∞—Ж–Є–Є UI/API —В–µ—Б—В–Њ–≤. –Ю–љ –Ї—А–Є—В–Є—З–µ—Б–Ї–Є –≤–∞–ґ–µ–љ:
вАФ –≤ –Ј–∞–Ї—А—Л—В—Л—Е –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ—Л—Е —Б–µ—В—П—Е,
вАФ –њ—А–Є —А–∞–±–Њ—В–µ —Б NDA-–њ—А–Њ–µ–Ї—В–∞–Љ–Є,
вАФ –і–ї—П –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є –Ј–∞—В—А–∞—В.
–Ґ–µ–Љ –љ–µ –Љ–µ–љ–µ–µ, –ї–Њ–Ї–∞–ї—М–љ—Л–є inference —В—А–µ–±—Г–µ—В —В–Њ—З–љ–Њ–є –љ–∞—Б—В—А–Њ–є–Ї–Є, –Ј–љ–∞–љ–Є—П –і–Њ—Б—В—Г–њ–љ—Л—Е –∞—А—Е–Є—В–µ–Ї—В—Г—А (Qwen, DeepSeek, LLaMA) –Є –љ–∞–ї–Є—З–Є—П —Е–Њ—В—П –±—Л
–У–ї–∞–≤–љ–Њ–µ –Њ –ї–Њ–Ї–∞–ї—М–љ–Њ–Љ –Є–љ—Д–µ—А–µ–љ—Б–µ
вАФ –Ы–Њ–Ї–∞–ї—М–љ—Л–є –Ј–∞–њ—Г—Б–Ї –Љ–Њ–і–µ–ї–µ–є —А–∞–±–Њ—В–∞–µ—В вАФ –Є —Б—В–∞–±–Є–ї—М–љ–Њ –љ–∞ M1/M2, –љ–Њ —В–Њ–ї—М–Ї–Њ —Б –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ–љ—Л–Љ–Є –≤–µ—А—Б–Є—П–Љ–Є (Qwen, DeepSeek Distill, GPT-2/3).
вАФ DeepSeek-R1-Distill-Qwen-1.5B вАФ —Е–Њ—А–Њ—И–Є–є –±–∞–ї–∞–љ—Б: <4 –У–С –њ–∞–Љ—П—В–Є, –±—Л—Б—В—А—Л–є –Њ—В–≤–µ—В, –њ–Њ–і–і–µ—А–ґ–Ї–∞ —Б–ї–Њ–ґ–љ—Л—Е —И–∞–≥–Њ–≤.
вАФ –Ш–љ—В–µ–≥—А–∞—Ж–Є—П —Б —В–µ—Б—В–Є—А—Г—О—Й–Є–Љ —Д—А–µ–є–Љ–≤–Њ—А–Ї–Њ–Љ Playwright –њ–Њ–Ј–≤–Њ–ї—П–µ—В –∞–≤—В–Њ–Љ–∞—В–Є–Ј–Є—А–Њ–≤–∞—В—М UI-–њ–Њ–Ї—А—Л—В–Є–µ.
вАФ –Э–µ–Њ–±—Е–Њ–і–Є–Љ–∞ –њ—А–Њ–≤–µ—А–Ї–∞: –љ–µ –≤—Б–µ –Љ–Њ–і–µ–ї–Є –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—О—В –Ї–Њ—А—А–µ–Ї—В–љ—Г—О –≥–µ–љ–µ—А–∞—Ж–Є—О —И–∞–≥–Њ–≤/–Њ–ґ–Є–і–∞–љ–Є–є –±–µ–Ј fine-tuning.
вАФ –§–Њ—А–Љ—Г–ї—Л —А–∞—Б—З—С—В–∞ —А–µ—Б—Г—А—Б–Њ—С–Љ–Ї–Њ—Б—В–Є –Є —Б–Ї–Њ—А–Њ—Б—В–Є –њ–Њ–Ј–≤–Њ–ї—П—О—В –њ–Њ–і–Њ–±—А–∞—В—М –њ—А–∞–≤–Є–ї—М–љ—Г—О –Љ–Њ–і–µ–ї—М –њ–Њ–і –ґ–µ–ї–µ–Ј–Њ.
–°–њ–Є—Б–Њ–Ї –Є—Б—В–Њ—З–љ–Є–Ї–Њ–≤:
1. –¶–Ј–Є-–¶–∞–є –ѓ–љ, –¶–Ј—О–љ—М-–Ы—Г–љ –•—Г–∞–љ, –§—Н–љ-–¶–Ј—П–љ—М –Т–∞–љ, –£–Є–ї—М—П–Љ –Є –І. –І—Г. –Я–Њ—Б—В—А–Њ–µ–љ–Є–µ –Њ–±—К–µ–Ї—В–љ–Њ-–Њ—А–Є–µ–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ–є –∞—А—Е–Є—В–µ–Ї—В—Г—А—Л –і–ї—П —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П –≤–µ–±-–њ—А–Є–ї–Њ–ґ–µ–љ–Є–є. –Ц—Г—А–љ–∞–ї –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Њ–љ–љ—Л—Е –љ–∞—Г–Ї –Є —В–µ—Е–љ–Є–Ї–Є, —П–љ–≤–∞—А—М 2016.
2. –¶–Ј–Є-–¶–∞–є –ѓ–љ, –¶–Ј—О–љ—М-–Ы—Г–љ –•—Г–∞–љ, –§—Н–љ-–¶–Ј—П–љ—М –Т–∞–љ –Є –£–Є–ї—М—П–Љ –Ъ. –І—Г. –Ю–±—К–µ–Ї—В–љ–Њ-–Њ—А–Є–µ–љ—В–Є—А–Њ–≤–∞–љ–љ–∞—П –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞, –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—О—Й–∞—П —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–µ –≤–µ–±-–њ—А–Є–ї–Њ–ґ–µ–љ–Є–є. –Ь–∞—В–µ—А–Є–∞–ї—Л
3. –§–Є–ї–Є–њ–њ–Њ –†–Є–Ї–Ї–∞ –Є –Я–∞–Њ–ї–Њ –Ґ–Њ–љ–µ–ї–ї–∞. –Р–љ–∞–ї–Є–Ј –≤–µ–±-—Б–∞–є—В–∞: –°—В—А—Г–Ї—В—Г—А–∞ –Є —Н–≤–Њ–ї—О—Ж–Є—П. –Т –Љ–∞—В–µ—А–Є–∞–ї–∞—Е
4. –§–Є–ї–Є–њ–њ–Њ –†–Є–Ї–Ї–∞ –Є –Я–∞–Њ–ї–Њ –Ґ–Њ–љ–µ–ї–ї–∞. –Р–љ–∞–ї–Є–Ј –Є —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–µ –≤–µ–±-–њ—А–Є–ї–Њ–ґ–µ–љ–Є–є. –Т –Љ–∞—В–µ—А–Є–∞–ї–∞—Е
5. –§–Є–ї–Є–њ–њ–Њ –†–Є–Ї–Ї–∞ –Є –Я–∞–Њ–ї–Њ –Ґ–Њ–љ–µ–ї–ї–∞. –Я—А–Њ—Ж–µ—Б—Б—Л —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П –≤–µ–±-–њ—А–Є–ї–Њ–ґ–µ–љ–Є–є. –Р–љ–љ–∞–ї—Л —А–∞–Ј—А–∞–±–Њ—В–Ї–Є –њ—А–Њ–≥—А–∞–Љ–Љ–љ–Њ–≥–Њ –Њ–±–µ—Б–њ–µ—З–µ–љ–Є—П,
6. –Ь–∞–є–Ї–ї –С–µ–љ–µ–і–Є–Ї—В, –Ф–ґ—Г–ї–Є–∞–љ–∞ –§—А–µ–є—А–µ –Є –Я–∞—В—А–Є—Б –У–Њ–і—Д—А—Г–∞. Veriweb: –Т –Љ–∞—В–µ—А–Є–∞–ї–∞—Е
7. –°–µ–±–∞—Б—В—М—П–љ –≠–ї—М–±–∞—Г–Љ, –°—А–Є–Ї–∞–љ—В –Ъ–∞—А—А–µ –Є –У—А–µ–≥–≥ –†–Њ—В–µ—А–Љ–µ–ї. –Т —Е–Њ–і–µ —А–∞–Ј–±–Є—А–∞—В–µ–ї—М—Б—В–≤






